Performance von Apache Cassandra: alles, was Sie darüber wissen wollten


Alex Bekker ist Leiter der Abteilung Data Analytics in ScienceSoft, einem Unternehmen für IT-Beratung und Softwareentwicklung. Alex hat mehrere Projekte in den Bereichen wie Business Intelligence, Big Data, Data Analytics geleitet und auch den Unternehmen geholfen, die Vorteile von Data Science und maschinellem Lernen zu nutzen. Zu seinen größten Projekten gehören: Big-Data-Analyse für die Musterendeckung in der Mediennutzung in mehr als 10 Ländern; die Analyse von Eigenmarken-Produkten für mehr als 18.500 Produzenten, BI für 200 Gesundheitszentren.
Na klar, Apache Cassandra kann die Zukunft nicht voraussagen. Was Cassandra als Open-Source Datenbank-Management-System aber wirklich gut machen kann - eine Datenspeicherung so organisieren, dass die Verarbeitung großer Datenmengen möglich wird. Ich möchte darauf hinweisen, dass es um wirklich große Datenmengen geht, wodurch besondere Anforderungen an die Datenverwaltung entstehen. Aber wie gut ist Apache Cassandra dabei? Lesen Sie darüber in unserem Blogbeitrag, damit Ihnen die Performance von Cassandra nicht mehr spanisch vorkommt.

Begriffe, die Sie vielleicht noch nicht kennen
Im Folgenden verwenden wir ziemlich viele spezifische Begriffe, die Sie vielleicht zum ersten Mal sehen. Hier werden ihre kurzen Erklärungen gegeben.
Der Token ist eine etwas abstrakte Zahl (Identifizierer), die absteigend jedem Knoten in einem Cluster zugeordnet wird. Alle Knoten formen einen Token-Ring.
Der Partitionierer ist ein Algorithmus, der entscheidet, welche Knoten im Cluster im Begriff sind, Daten zu speichern.
Der Replikationsfaktor bestimmt die Anzahl der Replikate von Daten.
Der Schlüsselraum (Keyspace) ist ein globaler Speicherplatz, der alle Spaltenfamilien einer Anwendung enthält.
Die Spaltenfamilie (Column Family) ist eine Menge von den kleinsten Einheiten (Spalten) in Cassandra zur Datenspeicherung. Spalten bestehen aus einem Spaltennamen (Schlüssel; eng. Key), einem Wert (Value) und einem Zeitstempel (Timestamp).
Die Memtable ist eine Cache-Speicherstruktur.
Die SSTable ist eine unveränderbare Datenstruktur, die erstellt wird, sobald eine Memtable auf eine Festplatte ausgelagert wird.
Der Primärindex ist ein Teil von SSTable, der eine Menge von Zeilenschlüsseln (Row Keys) dieser Tabelle enthält und auf die Position der Schlüssel in dieser SSTable verweist.
Der Primärschlüssel (Primary Key) in Cassandra besteht aus einem Partitionsschlüssel (Partition Key) und einer Anzahl von Clustering-Spalten (falls sie vorhanden sind). Der Partitionsschlüssel hilft beim Verständnis, auf welchen Knoten Daten gespeichert werden, während Clustering-Spalten Daten in der Tabelle in aufsteigender alphabetischer Reihenfolge (normalerweise) organisieren.
Die Bloom-Filter sind Datenstrukturen, die verwendet werden, um schnell zu finden, welche SSTables die erforderlichen Daten haben können.
Die Sekundärindizes (Secondary Indexes) können Daten innerhalb eines einzelnen Knotens anhand seiner Nicht-Primärschlüsselspalten lokalisieren. SASI (SSTable Attached Secondary Index) ist eine verbesserte Version eines Sekundärindexes, der den SSTables „beigefügt“ ist.
Die materialisierte Sicht (Materialized View) ist eine Methode der „Cluster-weiten“ Indexierung, die eine andere Variante der Basistabelle erstellt, aber die abgefragten Spalten in den Partitionsschlüssel aufnimmt (während sie bei einem Sekundärindex nicht berücksichtigt werden). Auf diese Weise können Sie nach indizierten Daten im gesamten Cluster suchen, ohne in jeden Knoten hinzuschauen.
Datenmodellierung in Apache Cassandra
Die Performance von Apache Cassandra hängt stark von der Art und Weise ab, wie das Datenmodell entworfen ist. Bevor Sie also darin eintauchen, stellen Sie sicher, dass Sie drei „Dogmen“ der Datenmodellierung von Cassandra verstehen:
- Festplattenspeicher ist billig.
- Schreiboperationen sind billig.
- Netzwerkkommunikation ist teuer.
Diese drei Aussagen enthüllen die wahre Bedeutung aller in diesem Artikel beschriebenen Besonderheiten von Cassandra.
Und was die wichtigsten Regeln betrifft, die beim Entwurf eines Cassandra-Datenmodells zu beachten sind, sind das die folgenden:
- Verteilen Sie Daten gleichmäßig im Cluster, das heißt, dass Sie einen guten Primärschlüssel haben.
- Reduzieren Sie die Anzahl der Partitionslesevorgänge, das heißt, dass Sie zuerst über die zukünftigen Abfragen denken, bevor Sie Daten modellieren.
Datenpartitionierung und Denormalisierung
Um die Performance von Apache Cassandra zu bewerten, ist es logisch, am Anfang eines Datenwegs zu beginnen und zuerst seine Effizienz beim Verteilen und Duplizieren von Daten zu prüfen.
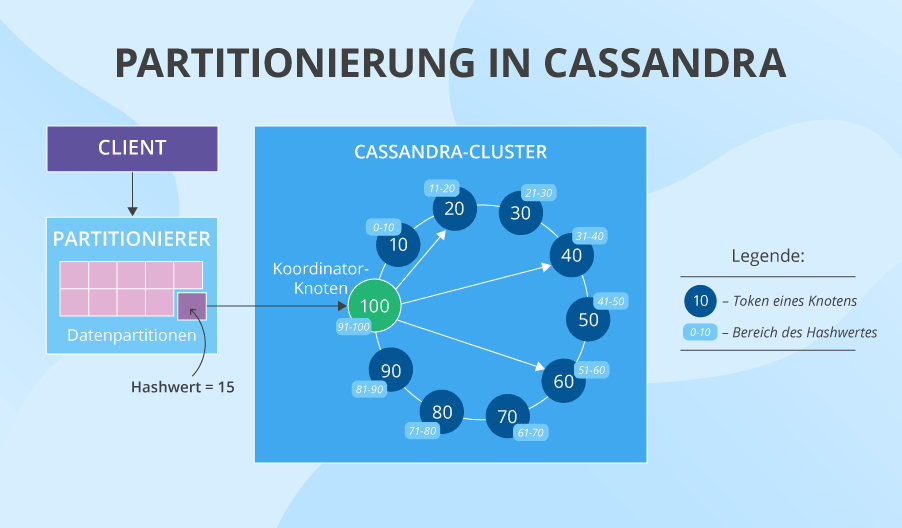
Partitionierung und Denormalisierung: der Prozess
Während der Datenverteilung verwendet Apache Cassandra eine konsistente Hashingfunktion (Consistent Hashing) und repliziert und partitioniert die Daten. Stellen Sie sich vor, wir haben 10 Cluster mit den Token 10, 20, 30, 40 usw. Ein Partitionierer konvertiert den Primärschlüssel von Daten in einen bestimmten Hashwert (z.B.15) und schaut dann auf den Token-Ring. Der erste Knoten, dessen Token größer als Hashwert ist, wird die erste Wahl dafür sein, Daten zu speichern. Und wenn wir den Replikationsfaktor von 3 haben (normalerweise ist es 3, aber es ist für jeden Schlüsselraum einstellbar), speichern die nächsten zwei Knoten, deren Token noch größer sind (oder diejenigen, die sich physisch in der Nähe des ersten Knotens befinden) auch die Daten. So leicht erhalten wir Replikate von Daten auf drei verschiedenen Knoten. Darüber hinaus praktiziert Cassandra auch Denormalisierung und unterstützt die Duplizierung von Daten, indem sie mehrere Versionen einer und derselben Tabelle erstellt, die für unterschiedliche Lesevorgänge optimiert sind. Stellen Sie sich vor, wie viele Daten es gibt, wenn wir dieselbe riesige denormalisierte Tabelle mit wiederholten Daten auf 3 Knoten haben und jeder Knoten auch mindestens 3 Versionen dieser Tabelle hat.
Partitionierung und Denormalisierung: der Nachteil
Die Tatsache, dass Daten in Apache Cassandra denormalisiert sind, kann seltsam scheinen, wenn Sie von den Erfahrungen mit einer relationalen Datenbank ausgehen. Wenn ein Nicht-Big-Data-System seine Maßstäbe vergrößert, müssen Sie solche Dinge wie Lese-Replikation, Sharding und Indexoptimierung tun. Aber dann nach einer Weile wird Ihr System fast nicht funktionsfähig sein, und Sie verstehen, dass das großartige relationale Modell mit all seinen Joins und Normalisierung der genaue Grund für Leistungsprobleme ist.
Cassandra löst diese durch Denormalisierung und Erstellung von mehreren Versionen einer Tabelle, die für unterschiedliche Lesevorgänge optimiert sind. Aber diese "Hilfe" bleibt nicht ohne Folgen. Wenn Sie entscheiden, Ihre Lese-Performance zu erhöhen, indem Sie Replikate von Daten und doppelte Tabellenversionen erstellen, leidet die Schreib-Performance, weil Sie nur einmal schreiben schon nicht können. Sie müssen dasselbe x-mal schreiben. Außerdem brauchen Sie einen guten Mechanismus, um zu wählen, auf welchen Knoten zu schreiben, was Apache Cassandra anbietet, also hier kann man keine Vorwürfe machen. Und obwohl diese Verluste für die Schreib-Performance in Cassandra nicht groß sind und oft vernachlässigt werden, benötigen Sie immer noch die Ressourcen für mehrfache Schreibvorgänge.
Partitionierung und Denormalisierung: der Vorteil
Konsistentes Hashing ist sehr effizient für die Datenpartitionierung. Warum? Da der Token-Ring eine ganze Reihe von all möglichen Schlüsseln abdeckt, werden die Daten gleichmäßig darunter verteilt, indem jeder der Knoten ungefähr gleich geladen wird. Aber das Angenehmste daran ist, dass die Leistung Ihres Clusters fast linear skalierbar ist. Es klingt zu gut, um wahr zu sein, aber es ist so. Wenn Sie die Anzahl der Knoten verdoppeln, verringert sich der Abstand zwischen ihren Token um die Hälfte, und das System wird folglich in der Lage sein, fast doppelt so viele Lese- und Schreibvorgänge zu verarbeiten. Der zusätzliche Bonus hier: Mit doppelten Knoten wird Ihr System noch fehlertoleranter.
Das Schreiben

Das Schreiben: der Prozess
Nachdem eine Schreibanforderung an einen bestimmten Knoten gerichtet wurde, wird sie zuerst an das Commit-Log gesendet (es speichert alle Informationen über Schreibvorgänge im Cache). Gleichzeitig werden die Daten in einer Memtable gespeichert. An einem bestimmten Punkt (zum Beispiel, wenn die Memtable voll ist), lagert Cassandra die Daten aus dem Cache auf die Festplatte aus -– in SSTables. In demselben Moment wird das Commit-Log von allen seinen Daten geleert, weil es nicht mehr die entsprechenden Daten im Cache in Acht nehmen muss. Nachdem ein Knoten die Daten geschrieben hat, benachrichtigt er den Koordinator-Knoten darüber, dass die Operation erfolgreich abgeschlossen ist. Und die Anzahl solcher Erfolgsmeldungen hängt von dem Konsistenz-Level von Daten für das Schreiben ab, das Ihre Cassandra-Praktiker festlegen.
Solch ein Prozess läuft auf allen Knoten ab, die sich daranmachen, Partitionen zu schreiben. Aber was geschieht, wenn einer davon ausfällt? Es gibt eine elegante Lösung dafür – Hinted Handoff. Wenn der Koordinator erkennt, dass ein Replikat-Knoten nicht antwortet, wird der verpasste Schreibvorgang auf dem Koordinator gespeichert. Dann erstellt Cassandra vorübergehend im lokalen Schlüsselraum einen Hinweis, der den "entgleisten" Knoten später daran erinnert, bestimmte Daten zu schreiben, nachdem er wieder hochkommt. Wenn der Knoten innerhalb von 3 Stunden nicht wiederhergestellt wird, speichert der Koordinator den Schreibvorgang dauerhaft.
Das Schreiben: der Nachteil
Trotzdem ist der Schreibvorgang nicht perfekt. Hier sind einige enttäuschende Dinge:
- Append-Operationen funktionieren einwandfrei, während Aktualisierungen in Cassandra konzeptionell fehlen (obwohl das nicht ganz richtig ist, so zu sagen, weil ein solcher Befehl existiert). Wenn Sie einen bestimmten Wert aktualisieren müssen, fügen Sie einfach einen Eintrag mit demselben Primärschlüssel, aber mit einem neuen Wert und einem aktuellen Zeitstempel hinzu. Stellen Sie sich vor, wie viele Aktualisiserungen Sie benötigen können und wie viel Speicherplatz das einnimmt. Des Weiteren kann das die Lese-Performance beeinflussen, weil Cassandra eine Menge an Daten in einem einzelnen Schlüssel durchsehen muss und prüfen soll, welche davon die neuesten sind. Hin und wieder wird jedoch eine Komprimierung durchgeführt, um solche Daten zusammenzuführen und Speicherplatz freizugeben.
- Das Verfahren von Hinted Handoff kann den Koordinator überlasten. Falls das passiert, wird der Koordinator Schreibvorgänge ablehnen, was zum Verlust einiger Replikate von Daten führen kann.
Das Schreiben: der Vorteil
Die Schreib-Performance von Apache Cassandra ist jedoch immer noch ziemlich gut. Hier ist warum:
- Cassandra vermeidet zufällige Dateneingabe, indem sie ein klares Szenario darüber hat, wie es läuft. Das trägt zur Schreib-Performance bei.
- Um sicherzustellen, dass alle ausgewählten Knoten die Daten schreiben, selbst wenn einige davon ausfallen, steht das oben erwähnte Verfahren von Hinted Handoff zur Verfügung. Sie sollten jedoch beachten, dass der Hinted Handoff nur dann funktioniert, wenn Ihr Konsistenz-Level erreicht ist.
- Das Design des Schreibvorgangs beinhaltet das Commit-Log, was nett ist. Warum? Wenn ein Knoten ausfällt, wird das Commit-Log, nachdem der Knoten wieder hochkommt, alle verlorenen Schreibvorgänge im Cache in einer Memtable wiederherstellen.
Das Lesen
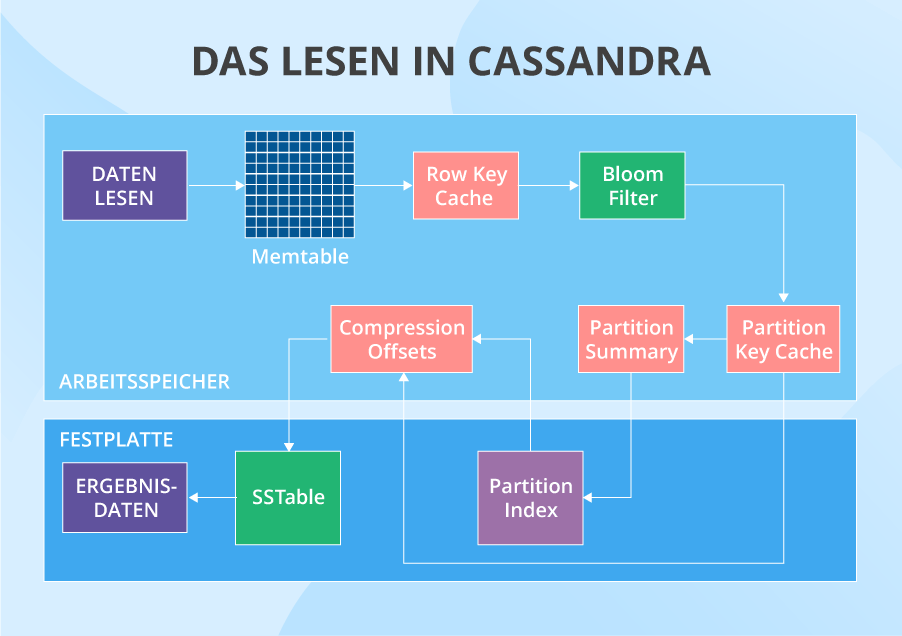
Das Lesen: der Prozess
Wenn ein Lesevorgang ihre Reise beginnt, wird der Partitionsschlüssel der Daten verwendet, um die Knoten, wo die Daten vorliegen, zu finden. Danach wird die Anfrage an so eine Anzahl von Knoten gesendet, die das anpassbare Konsistenz-Level für das Lesen spezifiziert. Dann überprüft Cassandra auf jedem Knoten in einer bestimmten Reihenfolge verschiedene Orte, an denen die Daten liegen können. Der erste ist die Memtable. Wenn die Daten dort nicht vorhanden sind, überprüft sie den Row Key Cache (falls aktiviert), dann den Bloom-Filter und dann den Partition Key Cache (auch wenn er aktiviert ist). Wenn der Partition Key Cache über den erforderlichen Partitionsschlüssel verfügt, geht Cassandra direkt zu den Compression Offsets über und holt schließlich die erforderlichen Daten aus einer bestimmten SSTable. Wenn der Partitionsschlüssel im Partition Key Cache nicht gefunden wurde, überprüft Cassandra die Partition Summary und dann den Primärindex, bevor sie zu den Compression Offsets übergeht und die Daten aus der SSTable extrahiert.
Nachdem die Daten mit dem letzten Zeitstempel gefunden wurden, werden sie zum Koordinator abgerufen. Hier tritt eine weitere Stufe des Lesens auf. Wie wir hier festgestellt haben, hat Apache Cassandra Probleme mit der Datenkonsistenz. Die Sache ist so, dass Sie viele Replikaten von Daten schreiben und ihre alten Versionen anstatt der neueren lesen können. Aber Cassandra ignoriert diese konsistenzbezogenen Probleme nicht: sie versucht sie mit einem Read-Repair Verfahren zu lösen. Die Knoten, die in den Lesevorgang einbezogen sind, geben ihre Ergebnisse zurück. Dann vergleicht Cassandra diese Ergebnisse basierend auf der Strategie "Das letzte Schreiben gewinnt". Daher ist die neue Datenversion der Hauptkandidat, der an den Benutzer zurückgegeben werden kann, während die älteren Versionen auf ihren Knoten umgeschrieben werden. Aber das ist nicht alles. Im Hintergrund überprüft Cassandra den Rest der Knoten, die abgefragten Daten haben (denn der Replikationsfaktor ist oft größer als das Konsistenz-Level). Wenn diese Knoten ihre Ergebnisse zurückgeben, vergleicht die DB auch sie, und die älteren werden aktualisiert. Erst danach erhält der Benutzer das Ergebnis.
Das Lesen: der Nachteil
Die Lese-Performance von Apache Cassandra genießt viel ihren Ruhm, aber sie ist immer noch nicht völlig einwandfrei.
- Alles ist in Ordnung, solange Sie Ihre Daten nur mithilfe vom Partitionsschlüssel abfragen. Wenn Sie das mithilfe von einer Spalte, die außerhalb des Partitionsschlüssels ist, tun möchten (indem Sie den Sekundärindex oder einen SASI verwenden), geht es abwärts. Das Problem besteht darin, dass Sekundärindizes und SASIs den Partitionsschlüssel nicht enthalten, d.h, es gibt keine Möglichkeit zu wissen, welcher Knoten die indizierten Daten speichert. Es führt zur Suche nach den Daten auf allen Knoten im Cluster, was weder billig noch schnell ist.
- Sowohl der Sekundärindex als auch der SASI sind nicht für Spalten mit hoher Kardinalität geeignet (ebenso wie für Zähler und statische Spalten). Das Verwenden von diesen Indizes für die "seltenen" Daten kann die Lese-Performance hinreichend verringern.
- Die Bloom-Filter basieren auf probabilistischen Algorithmen und sind dafür bestimmt, sehr schnell Ergebnisse zu bringen. Das führt oft zu Fehlalarmen, was eine weitere Möglichkeit darstellt, Zeit und Ressourcen zu verschwenden, während an den falschen Stellen gesucht wird.
- Neben dem Lesen können Sekundärindizes, SASIs und materialisierte Sichten das Schreiben beeinträchtigen. Im Fall mit SASI und Sekundärindex, jedes Mal, wenn Daten in eine Tabelle mit der indizierten Spalte geschrieben werden, müssen die Spaltenfamilien, die die Indizes enthalten, und Ihre Werte aktualisiert werden. Und im Fall mit materialisierter Sicht muss sie selbst geändert werden, wenn etwas Neues in die Basistabelle geschrieben wird.
- Wenn Sie eine Tabelle mit Tausenden von Spalten lesen müssen, können Sie Probleme haben. Cassandra hat Einschränkungen hinsichtlich der Partitionsgröße und Anzahl der Werte: 100 MB und 2 Mrd. entsprechend. Wenn Ihre Tabelle also zu viele Spalten und Werte enthält oder zu groß ist, sind Sie nicht imstande, sie schnell zu lesen. Oder wird es überhaupt unmöglich, sie zu lesen. Und das ist zu beachten. Wenn die Aufgabe das direkt nicht erfordert, diese Anzahl von Spalten zu lesen, ist es immer besser, solche Tabellen in mehrere Teile aufzuteilen. Außerdem sollten Sie daran denken, dass je mehr Spalten die Tabelle hat, desto mehr RAM (Arbeitsspeicher) Sie benötigen werden, um diese zu lesen.
Das Lesen: der Vorteil
Keine Angst, die Lese-Performance hat auch starke Seiten.
- Cassandra bietet eine aufregend stabile Datenverfügbarkeit. Es existiert kein Single Point of Failure (einzelne Stelle des Scheiterns), plus, sie speichert Daten auf zahlreichen Knoten und an zahlreichen Orten. Wenn also mehrere Knoten ausgefallen sind (bis zur Hälfte des Clusters), werden Sie Ihre Daten trotzdem lesen (sofern Ihr Replikationsfaktor entsprechend eingestellt ist).
- Die Konsistenzprobleme können in Cassandra durch das geschickte und schnelle Read-Repair-Verfahren gelöst werden. Es ist sehr effizient und sehr hilfreich, aber immer noch können wir es nicht sagen, dass dieses Verfahren jederzeit perfekt funktioniert.
- Sie denken vielleicht, dass der Lesevorgang zu lang dauert und dass zu viele Bereiche überprüft werden, was ineffizient ist, wenn es um die Abfrage häufig aufgerufener Daten geht. Aber Cassandra hat einen zusätzlichen verkürzten Lesevorgang für oft erforderliche Daten. Für solche Fälle können die Daten selbst in einem Row Cache gespeichert werden. Oder ihre "Adresse" kann im Key Cache sein, was den Prozess sehr erleichtert.
- Sekundärindizes können immer noch nützlich sein, wenn wir über irgendwelche analytische Anfragen sprechen, wenn Sie auf alle oder fast alle Knoten zugreifen müssen.
- SASIs können ein sehr gutes Werkzeug für die Durchführung von Volltextsuchen sein.
- Die bloße Existenz von materialisierten Sichten kann als Vorteil angesehen werden, weil sie Ihnen ermöglichen, die erforderlichen indizierten Spalten im Cluster leicht zu finden. Obwohl das Erstellen zusätzlicher Tabellenvarianten Platz einnehmen wird.
Performance von Apache Cassandra: Fazit
Selbstverständlich ist niemand ohne Sünde. Apache Cassandra ist keine Ausnahme. Einige Aspekte können tatsächlich die Lese- und Schreibe-Performance stark beeinflussen, insbesondere wenn Ihr Datenmodel schlecht entworfen ist. Aber das bedeutet nicht, dass Apache Cassandra ein leistungsschwaches Produkt ist. Im Vergleich zu MongoDB und HBase hinsichtlich ihrer Leistung bei einer gemischten operativen und analytischen Arbeitsbelastung ist Cassandra – mit all seinen Stolpersteinen – bei weitem die beste aus diesen drei (was nur beweist, dass die NoSQL-Welt wirklich entfernt davon ist, perfekt zu sein). Die hohe Leistungsfähigkeit von Apache Cassandra hängt jedoch von dem Fachwissen der Mitarbeiter ab, die Ihre Cassandra-Cluster behandeln. Also, wenn Sie Apache Cassandra wählen, gut gemacht! Wählen Sie nun die richtigen Leute aus, die damit arbeiten werden.
