Apache Cassandra vs. Hadoop Distributed File System: Wann jedes davon besser passt


Alex Bekker ist Leiter der Abteilung Data Analytics in ScienceSoft, einem Unternehmen für IT-Beratung und Softwareentwicklung. Alex hat mehrere Projekte in den Bereichen wie Business Intelligence, Big Data, Data Analytics geleitet und auch den Unternehmen geholfen, die Vorteile von Data Science und maschinellem Lernen zu nutzen. Zu seinen größten Projekten gehören: Big-Data-Analyse für die Musterendeckung in der Mediennutzung in mehr als 10 Ländern; die Analyse von Eigenmarken-Produkten für mehr als 18.500 Produzenten, BI für 200 Gesundheitszentren.
Apache Cassandra und Apache Hadoop sind Mitglieder derselben Familie – Apache Software Foundation. Wir hätten diese beiden Frameworks gegenüberstellen können, aber dieser Vergleich wäre nicht fair, weil Apache Hadoop ein Ökosystem ist, das mehrere Komponenten umfasst. Denn Cassandra ist für die Speicherung von Big Data verantwortlich, haben wir sein Äquivalent aus dem Hadoop-Ökosystem gewählt, und das war Hadoop Distributed File System (HDFS). Hier werden wir versuchen herauszufinden, ob Cassandra und HDFS wie Zwillinge sind, die vom Aussehen her identisch sind und nur unterschiedliche Namen tragen, oder eher ein Bruder und eine Schwester sind, die ähnlich aussehen, aber immerhin sehr unterschiedlich sind.
Master / Slave vs. masterlose Architektur
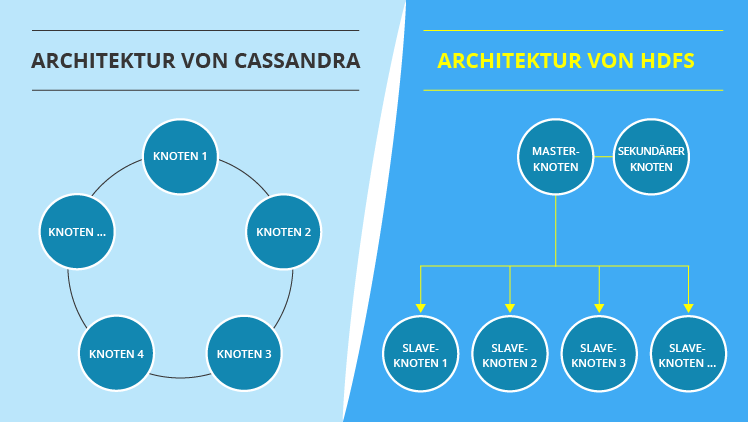
Bevor wir uns auf die Merkmale konzentrieren, durch die sich Hadoop Distributed File System (HDFS) und Cassandra auszeichnen, sollten wir die Besonderheiten ihrer Architekturen verstehen, denn sie sind der Grund für viele Unterschiede in der Funktionalität. Wenn Sie sich das Bild unten ansehen, werden Sie zwei gegensätzliche Konzepte sehen. Die Architektur von HDFS ist hierarchisch. Sie enthält einen Master-Knoten sowie zahlreiche Slave-Knoten. Im Gegensatz dazu besteht die Architektur von Cassandra aus mehreren Peer-to-Peer-Knoten und ähnelt einem Ring.
5 wichtige funktionale Unterschiede
1. Umgang mit massiven Datensätzen
Sowohl HDFS als auch Cassandra sind zum Speichern und Verarbeiten massiver Datenmengen konzipiert. Sie müssen aber zwischen diesen beiden Optionen wählen, abhängig von den Datensätzen, mit denen Sie zu tun haben. HDFS ist eine perfekte Wahl für das Schreiben großer Dateien. HDFS wurde entwickelt, um eine große Datei zu nehmen, sie in mehrere kleinere Dateien aufzuteilen und sie zwischen den Knoten zu verteilen. Wenn Sie einige Dateien aus HDFS lesen müssen, ist die Operation umgekehrt: HDFS muss mehrere Dateien von verschiedenen Knoten sammeln und ein Ergebnis liefern, das Ihrer Abfrage entspricht. Im Gegensatz dazu ist Cassandra die perfekte Wahl zum Schreiben und Lesen von mehreren kleineren Datensätzen. Seine masterlose Architektur ermöglicht schnelles Schreiben und Lesen bei jedem Knoten. Deshalb entscheiden sich IT-Lösungsarchitekten für Cassandra, wenn sie mit Zeitreihen arbeiten müssen, die gewöhnlich die Grundlage für das Internet der Dinge bilden.
Während sich HDFS und Cassandra in der Theorie gegenseitig ausschließen, können sie im wirklichen Leben nebeneinander existieren. Wenn wir weiter zum Thema „Big Data im IoT“ kommen, können wir ein Szenario entwickeln, in dem HDFS für ein Data Lake verwendet wird. In diesem Fall werden neue Messwerte zu Hadoop-Dateien hinzugefügt (z. B. es gibt eine separate Datei für jeden Sensor). Gleichzeitig kann ein Data Warehouse auf Cassandra aufgebaut werden.
2. Widerstandsfähigkeit gegen Ausfälle
Sowohl HDFS als auch Cassandra gelten als zuverlässig und fehlertolerant. Um das sicherzustellen, wenden beide Replikation an. Einfach gesagt, wenn Sie einen Datensatz speichern müssen, verteilen HDFS und Cassandra ihn auf irgendeinem Knoten und erstellen die Kopien des Datensatzes, um sie auf mehreren anderen Knoten zu speichern. Das Prinzip der Fehlertoleranz ist einfach: Fällt ein Knoten aus, sind die darin enthaltenen Datensätze nicht unwiederbringlich verloren – ihre Kopien sind auf anderen Knoten noch verfügbar. Beispielsweise erstellt HDFS standardmäßig drei Kopien, Sie können jedoch auch eine beliebige andere Anzahl von Replikaten festlegen. Vergessen Sie nicht, dass mehr Kopien mehr Speicherplatz und mehr Zeit für die Ausführung des Vorgangs bedeuten. Cassandra ermöglicht auch die Auswahl der erforderlichen Replikationsparameter.
Mit seiner masterlosen Architektur ist Cassandra jedoch zuverlässiger. Wenn der Master-Knoten und der sekundäre Knoten von HDFS versagen, gehen alle Datensätze verloren, ohne dass eine Wiederherstellung möglich ist. Natürlich tritt der Fall nicht häufig auf, aber dennoch kann es passieren.
3. Sicherung der Datenkonsistenz
Das Konsistenzlevel von Daten bestimmt, wie viele Knoten bestätigen sollen, dass sie ein Replikat gespeichert haben, sodass die gesamte Schreiboperation als erfolgreich betrachtet wird. Im Falle von Leseoperationen bestimmt das Konsistenzlevel von Daten, wie viele Knoten antworten sollen, bevor die Daten an einen Benutzer zurückgegeben werden.
Hinsichtlich des Konsistenzlevels von Daten verhalten sich HDFS und Cassandra sehr unterschiedlich. Nehmen wir an, Sie bitten HDFS, eine Datei zu schreiben und zwei Replikate zu erstellen. In diesem Fall wird das System zuerst mit dem Knoten 5 kommunizieren, dann wird der Knoten 5 den Knoten 12 auffordern, eine Kopie zu speichern, und schließlich wird der Knoten 12 den Knoten 20 auffordern, dasselbe zu tun. Erst danach wird die Schreiboperation bestätigt.

Cassandra verwendet den sequentiellen Ansatz von HDFS nicht, deswegen gibt es keine Warteschlange. Außerdem können Sie mit Cassandra die Anzahl der Knoten angeben, die den Erfolg der Operation bestätigen sollen (die Anzahl kann im Bereich von einem Knoten, der antwortet, bis zu allen Knoten liegen). Ein weiterer Vorteil von Cassandra ist, dass es für jeden Schreib- und Lesevorgang unterschiedliche Konsistenzlevel von Daten ermöglicht. Wenn eine Leseoperation Inkonsistenzen zwischen Replikaten aufdeckt, initiiert Cassandra übrigens einen Read Repair Vorgang, um die inkonsistenten Daten zu aktualisieren.

4. Indexierung
Da beide Systeme mit enormen Datenmengen arbeiten, würde das Scanning nur eines bestimmten Teils von Big Data, statt ein vollständiges Scanning zu machen, die Systemgeschwindigkeit erhöhen. Indexierung ist genau das Feature, das es ermöglicht.
Sowohl Cassandra als auch HDFS unterstützen die Indexierung, aber auf unterschiedliche Weise. Während Cassandra über viele spezielle Techniken verfügt, um Daten schneller zu erhalten, und sogar mehrere Indexe erstellen kann, erreichen die Fähigkeiten von HDFS nur eine bestimmte Ebene - die Dateien, in die der ursprüngliche Datensatz aufgeteilt wurde. Die Indexierung auf der Datensatzebene kann aber mit Apache Hive erreicht werden.
5. Bereitstellung der Analyse
Obwohl die beiden, Cassandra und HDFS, für große Datenspeicher ausgelegt sind, haben sie immer noch mit Analytics zu tun. Nicht alleine, sondern in Kombination mit spezialisierten Big-Data-Frameworks wie Hadoop MapReduce oder Apache Spark.
Das Ökosystem von Apache Hadoop enthält bereits MapReduce und Apache Hive (eine Abfrage-Engine) zusammen mit HDFS. Wie wir oben beschrieben haben, hilft Apache Hive dabei, den Mangel an Indexierung auf Datensatzebene zu überwinden, was es ermöglicht, eine intensive Analyse zu beschleunigen, bei der der Zugriff auf Datensätze erforderlich ist. Wenn Sie jedoch die Funktionalität von Apache Spark benötigen, können Sie sich für dieses Framework entscheiden, weil es auch mit HDFS kompatibel ist.
Cassandra funktioniert auch reibungslos zusammen mit Hadoop MapReduce oder Apache Spark, die mit diesem Datenspeicher erfolgreich arbeiten können.
HDFS und Cassandra im Rahmen von CAP-Theorem
Nach dem CAP-Theorem (Consistency (Konsistenz), Availability (Verfügbarkei), Partition Tolerance (Partitionstoleranz)) kann ein verteiltes Dateisystem nur zwei der folgenden drei Funktionen unterstützen:
- Konsistenz: eine Garantie, dass die Daten immer aktuell und synchronisiert sind, was bedeutet, dass jeder Benutzer zu jedem Zeitpunkt die gleiche Antwort auf seine Leseanfrage erhält, egal, welcher Knoten ihn zurückgibt.
- Verfügbarkeit: eine Garantie, dass ein Benutzer innerhalb einer angemessenen Zeit immer eine Antwort vom System erhält.
- Partitionstoleranz: eine Garantie, dass das System auch dann weiter funktioniert, wenn einige seiner Komponenten ausfallen.
Wenn man HDFS und Cassandra aus der Perspektive des CAP-Theorems betrachtet, so repräsentiert das erstere CP und das letztere CP oder AP-Eigenschaften. Das bedeutet, dass Cassandra wahrscheinlich hinsichtlich der Arbeitsgeschwindigkeit HDFS übertreffen wird, aber der Datenkonsistenz halber.
Kurz gesagt
Wenn Sie zwischen Apache Cassandra und HDFS wählen müssen, müssen Sie zum Ersten die Art Ihrer Rohdaten berücksichtigen. Wenn Sie große Datenmengen speichern und verarbeiten müssen, können Sie HDSF in Erwägung ziehen, wenn es um mehrere kleine Datensätze geht – könnte Cassandra eine bessere Option sein. Außerdem sollten Sie Ihre Anforderungen in Bezug auf Datenkonsistenz, Verfügbarkeit und Partitionstoleranz formulieren. Um eine endgültige Entscheidung zu treffen, ist es wichtig, die genaue Verwendung von Big Data Storage zu verstehen.

Auch wenn Cassandra in den meisten beschriebenen Fällen HDFS zu übertreffen scheint, bedeutet das nicht, dass HDFS schwach ist. Basierend auf Ihren geschäftlichen Anforderungen kann ein professionelles Hadoop-Beratungsteam eine Kombination aus Frameworks und Technologien mit HDFS und Hive oder HBase vorschlagen, die eine großartige und nahtlose Leistung ermöglichen.
